









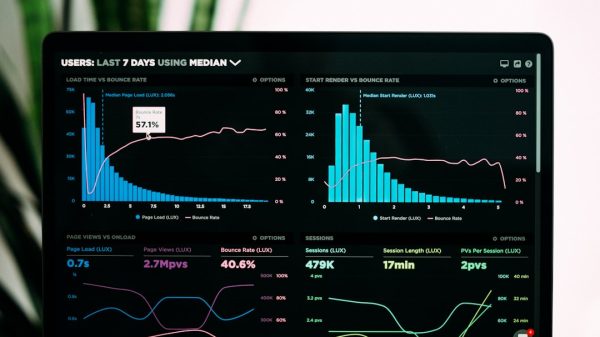











In modern technology operations, uptime is not a luxury; it is a baseline requirement. As organizations scale their infrastructure across cloud environments, data centers, edge devices, and distributed networks, traditional reactive maintenance models are no longer sufficient. Over the past several years, predictive maintenance has emerged as a transformative strategy, enabling tech operations teams to anticipate failures before they occur. One large-scale implementation recently demonstrated a 33% reduction in unplanned downtime, setting a new benchmark for operational resilience and efficiency.
TLDR: By implementing predictive maintenance powered by real-time monitoring, machine learning, and structured operational processes, a technology operations team reduced unplanned downtime by 33%. The shift from reactive to predictive workflows enabled earlier fault detection, more efficient resource allocation, and improved system reliability. The measurable impact included lower incident frequency, shorter mean time to repair, and significant cost avoidance. Predictive maintenance is no longer experimental—it is a proven operational advantage.
Predictive maintenance uses data analytics, performance telemetry, and behavioral modeling to anticipate equipment or system failure before it disrupts operations. Unlike reactive models, which respond after failures occur, or preventive schedules that rely on fixed timelines, predictive systems continuously assess asset health. They detect subtle patterns that precede outages, including performance drift, temperature anomalies, latency spikes, and irregular usage patterns.
From Reactive Firefighting to Proactive Intelligence
Before adopting predictive maintenance, the organization relied heavily on reactive incident management. Alerts were triggered when thresholds were breached, customers experienced service degradation, or systems became unavailable. Although incident response protocols were mature, the consequences were unavoidable:
- Frequent emergency interventions
- Unplanned service outages
- Overtime labor costs
- Customer dissatisfaction
- Inconsistent operational forecasting
Even with skilled engineers and modern monitoring tools, the fundamental limitation remained: the system only reported issues after degradation had begun. To break this cycle, leadership approved a structured predictive maintenance initiative focusing on critical infrastructure components including application servers, storage arrays, network devices, and virtualization clusters.
Image not found in postmetaBuilding the Predictive Framework
The transition to predictive maintenance required a multi-layered approach. It was not simply a technology upgrade; it was an operational redesign. The implementation included three core components:
1. Data Consolidation
Telemetry from diverse systems was centralized into a unified analytics platform. This included:
- CPU and memory usage trends
- Disk I/O performance metrics
- Network latency and packet loss rates
- Hardware temperature and power consumption logs
- Application-level performance indicators
Historical incident data covering three years was also integrated, enabling models to correlate prior failures with pre-incident conditions.
2. Machine Learning Modeling
Using supervised learning techniques, engineers trained models to identify early-stage anomaly signatures. Unlike static threshold alerts, these models recognized deviations from normal behavior patterns unique to each asset.
For example, a storage device might normally operate at 70% capacity with stable I/O patterns. A predictive model could detect micro-variations—such as inconsistent latency bursts combined with gradual temperature elevations—that historically preceded controller failure by several days.
3. Operational Workflow Redesign
Technology alone does not produce results. The organization established clear response protocols for predictive alerts:
- Severity classification guidelines
- Proactive maintenance scheduling windows
- Capacity redistribution procedures
- Executive visibility dashboards
This ensured predictive insights translated directly into preventive action.
Early Warning in Practice
Within the first three months, predictive alerts began identifying high-risk components that were still functioning within acceptable thresholds. In one critical instance, the system flagged abnormal vibration and temperature behavior in a rack-mounted server cluster supporting a core authentication platform.

No alarms had been triggered under legacy monitoring thresholds. However, historical pattern modeling associated this anomaly sequence with imminent power supply failure. Engineers scheduled a controlled maintenance window, replaced affected components, and redistributed load.
Post-event analysis confirmed that failure would likely have occurred within 48 hours, potentially impacting thousands of active sessions. Instead, service continuity was preserved without customer disruption.
Measuring the 33% Downtime Reduction
The reported 33% reduction was not anecdotal. It was calculated using standardized reliability metrics over a 12-month comparison period before and after implementation. Key performance indicators included:
- Unplanned downtime hours
- Mean Time Between Failures (MTBF)
- Mean Time to Repair (MTTR)
- Incident frequency per quarter
Results demonstrated:
- 33% reduction in total unplanned downtime hours
- 21% improvement in MTBF across core infrastructure
- 18% decrease in high-severity incidents
- 12% reduction in emergency maintenance labor costs
Importantly, these improvements were sustained beyond the initial implementation phase, indicating structural change rather than temporary optimization.
Financial and Strategic Impact
Reduced downtime generated measurable financial value. Depending on the organization’s industry, downtime can cost anywhere from thousands to millions of dollars per hour. By proactively preventing outages, the company avoided both direct revenue losses and indirect costs such as SLA penalties and reputational damage.
Beyond cost savings, predictive maintenance enabled stronger strategic positioning:
- Improved customer trust through higher service availability
- More accurate capacity forecasting
- Greater operational stability during peak demand
- Enhanced compliance with reliability standards
Executive stakeholders gained deeper visibility into infrastructure health, transforming IT operations from a reactive cost center into a predictable performance driver.
Operational Culture Shift
Perhaps the most profound impact was cultural. Engineers shifted from emergency responders to reliability strategists. Instead of constant high-pressure incident management, teams focused on data interpretation, systemic improvement, and preventive planning.
This cultural transformation included:
- Weekly predictive risk review meetings
- Cross-functional collaboration between operations and data science teams
- Ongoing model retraining based on new incident insights
- Clear accountability for preventive action completion
The result was higher employee satisfaction and reduced burnout, both common challenges in high-stress operations environments.
Challenges and Lessons Learned
The journey was not without difficulties. Early false positives created skepticism among engineers accustomed to deterministic alerts. To address this, the team implemented a calibration phase, refining sensitivity parameters and introducing confidence scoring.
Key lessons included:
- Start with high-value, high-risk assets before scaling
- Ensure historical incident data is clean and comprehensive
- Align predictive outputs with authorized maintenance windows
- Continuously retrain models to reflect infrastructure changes
Another critical insight was governance. Predictive maintenance requires clear ownership. Without defined responsibilities for acting on alerts, insights remain theoretical and do not translate into reduced downtime.
Scalability and Future Development
Following the documented success, the organization expanded predictive maintenance into additional domains, including:
- Cloud resource optimization
- Database transaction monitoring
- Edge device health tracking
- Cooling and environmental systems management
Advanced techniques such as anomaly clustering and reinforcement learning are now enhancing predictive accuracy. Over time, automation will likely play a larger role, enabling self-healing systems capable of reallocating resources without human intervention.
Nevertheless, human oversight remains essential. Predictive maintenance is most effective when paired with experienced operational judgment.
A Proven Operational Advantage
The 33% reduction in downtime demonstrates that predictive maintenance is not speculative innovation—it is a practical, scalable solution grounded in measurable results. By combining high-quality telemetry, intelligent modeling, and disciplined operational response, organizations can meaningfully improve reliability.
In technology operations, where constant availability defines competitiveness, proactive intelligence is becoming the standard rather than the exception. Organizations that continue to rely solely on reactive methods face increasing risk as infrastructure complexity grows.
Predictive maintenance transforms uncertainty into foresight. And in environments where minutes of downtime have significant consequences, foresight delivers measurable value.






